部署说明¶
1. 前置依赖¶
在使用本组件前,请确认系统环境已安装相关依赖软件,清单如下:
| 依赖软件 | 说明 | 备注 |
|---|---|---|
| FISCO-BCOS | >= 2.0, 1.x版本请参考V0.5版本 | |
| Bash | 需支持Bash(理论上来说支持所有ksh、zsh等其他unix shell,但未测试) | |
| Java | JDK[1.8] | JAVA安装可参考附录2 |
| Git | 下载的安装包使用Git | Git安装可参考附录3 |
| MySQL | >= mysql-community-server[5.7] | MySQL安装可参考附录4 |
| zookeeper | >= zookeeper[3.4] | 只有在进行集群部署的时候需要安装,zookeeper安装可参考附录5 |
| docker | >= docker[18.0.0] | 只有需要可视化监控页面的时候才需要安装,docker的安装可参考gitee docker安装手册 |
2. 部署步骤¶
2.1 获取安装包¶
2.1.1 下载安装包¶
#下载安装包
curl -LO https://github.com/WeBankFinTech/WeBASE-Codegen-Monkey/raw/master/src/main/install_scripts.tar.gz
#解压安装包
tar -zxf install_scripts.tar.gz
cd install_scripts
2.1.2 进入安装路径¶
进入解压后的install_scripts文件夹目录,获得如下的目录结构,其中Evidence.java为合约示例。
├── install_scripts
│ ├── config
│ │ ├── contract
│ │ │ └── HelloWorld.java
│ │ └── resources
│ │ └── application.properties
│ │ └── web3j.def
│ └── generate_bee.sh
2.2 配置安装包¶
2.2.1 配置合约文件¶
找到你的业务工程(你要导出数据的那条区块链中,往区块链写数据的工程),复制合约产生的Java文件:请将Java文件复制到./config/contract目录下(请先删除目录结构中的合约示例HelloWorld.java文件)。
如果你的业务工程并非Java工程,那就先找到你所有的合约代码。不清楚如何将Solidity合约生成为Java文件,请参考: 利用控制台将合约代码转换为java代码
2.2.3 配置应用¶
修改application.properties文件:该文件包含了所有的配置信息。以下配置信息是必须要修改的,否则跑不起来:
# 节点的IP及通讯端口、组号。
## NODE_NAME可以是任意字符和数字的组合,IP为节点运行的IP,PORT为节点运行的channel_port,默认为20200。
system.nodeStr=[NODE_NAME]@[IP]:[PORT]
## GROUP_ID必须与FISCO-BCOS中配置的groupId一致。
system.groupId=[GROUP_ID]
### 加密类型,根据FISCO BCOS链的加密类型配置,0-ECC, 1-gm。默认为非国密类型。
system.encryptType=0
# 数据库的信息,暂时只支持mysql; serverTimezone 用来设置时区
system.dbUrl=jdbc:mysql://[IP]:[PORT]/[database]?useSSL=false&serverTimezone=Asia/Shanghai&useUnicode=true&characterEncoding=UTF-8
system.dbUser=[user_name]
system.dbPassword=[password]
# 合约Java文件的包名
system.contractPackName=[编译Solidity合约时指定的包名]
更多配置详情可参考附录1:配置参数。
2.3 生成代码并运行程序¶
2.3.1 选择一:直接在本机运行¶
chmod +x generate_bee.sh
bash generate_bee.sh
## 还可以指定数据导出程序的版本,例如
## ./generate_bee.sh -v 1.3.0
当前目录下会生成WeBASE-Collect-Bee工程代码。数据导出组件将直接启动,对应的执行日志会打印到终端上。
请注意:请务必按照以上命令操作,切莫使用sudo命令来操作,否则会导致Gradlew没有权限,导致depot数据失败。
2.3.2 选择二:本机编译,复制执行包到其他服务器上运行¶
chmod +x generate_bee.sh
bash generate_bee.sh -e build
## 还可以指定数据导出程序的版本,例如
## ./generate_bee.sh -e build -v 1.3.0
当前目录下会生成WeBASE-Collect-Bee工程代码。请将此生成工程下的./WeBASE-Collect-Bee/WeBASE-Collect-Bee-core/dist文件夹复制到其他服务器上,并执行:
chmod +x *.sh
bash start.sh
tail -f *.log
2.3.3 选择三:本机编译,复制执行包到其他服务器,使用supervisor来启动。¶
使用supervisor来守护和管理进程,supervisor能将一个普通的命令行进程变为后台daemon,并监控进程状态,异常退出时能自动重启。 它是通过fork/exec的方式把这些被管理的进程当作supervisor的子进程来启动,这样只要在supervisor的配置文件中,把要管理的进程的可执行文件的路径写进去即可。也实现当子进程挂掉的时候,父进程可以准确获取子进程挂掉的信息的,可以选择是否自己启动和报警。 supervisor还提供了一个功能,可以为supervisord或者每个子进程,设置一个非root的user,这个user就可以管理它对应的进程。 编译生成代码的部署同2.2.3.2
使用supervisor来安装与部署的步骤请参阅附录6
2.4 检查运行状态及退出¶
2.4.1 检查程序进程是否正常运行¶
ps -ef |grep WeBASE-Collect-Bee
如果看到如下信息,则代表进程执行正常:
app 21980 24843 0 15:23 pts/3 00:00:44 java -jar WeBASE-Collect-Bee0.3.0-SNAPSHOT.jar
2.4.2 检查程序是否已经正常执行¶
当你看到程序运行,并在最后出现以下字样时,则代表运行成功:
Hibernate: select blockheigh0_.pk_id as pk_id1_2_, blockheigh0_.block_height as block_he2_2_, blockheigh0_.event_name as event_na3_2_, blockheigh0_.depot_updatetime as depot_up4_2_ from block_height_info blockheigh0_ where blockheigh0_.event_name=?
Hibernate: select blockheigh0_.pk_id as pk_id1_2_, blockheigh0_.block_height as block_he2_2_, blockheigh0_.event_name as event_na3_2_, blockheigh0_.depot_updatetime as depot_up4_2_ from block_height_info blockheigh0_ where blockheigh0_.event_name=?
Hibernate: select blockheigh0_.pk_id as pk_id1_2_, blockheigh0_.block_height as block_he2_2_, blockheigh0_.event_name as event_na3_2_, blockheigh0_.depot_updatetime as depot_up4_2_ from block_height_info blockheigh0_ where blockheigh0_.event_name=?
还可以通过以下命令来查看区块的同步状态:
tail -f webasebee-core.log| grep "sync block"
当看到以下滚动的日志时,则代表区块同步状态正常,开始执行下载任务。
$ tail -f webasebee-core.log| grep "sync block"
2019-05-05 14:41:07.348 INFO 60538 --- [main] c.w.w.c.service.CommonCrawlerService : Try to sync block number 0 to 90 of 90
2019-05-05 14:41:07.358 INFO 60538 --- [main] c.w.w.c.service.BlockTaskPoolService : Begin to prepare sync blocks from 0 to 90
2019-05-05 14:41:17.142 INFO 60538 --- [main] c.w.w.crawler.service.BlockSyncService : Block 0 of 90 sync block succeed.
2019-05-05 14:41:17.391 INFO 60538 --- [main] c.w.w.crawler.service.BlockSyncService : Block 1 of 90 sync block succeed.
2019-05-05 14:41:17.618 INFO 60538 --- [main] c.w.w.crawler.service.BlockSyncService : Block 2 of 90 sync block succeed.
2019-05-05 14:41:18.072 INFO 60538 --- [main] c.w.w.crawler.service.BlockSyncService : Block 3 of 90 sync block succeed.
2019-05-05 14:41:18.395 INFO 60538 --- [main] c.w.w.crawler.service.BlockSyncService : Block 4 of 90 sync block succeed.
2019-05-05 14:41:18.796 INFO 60538 --- [main] c.w.w.crawler.service.BlockSyncService : Block 5 of 90 sync block succeed.
2019-05-05 14:41:19.008 INFO 60538 --- [main] c.w.w.crawler.service.BlockSyncService : Block 6 of 90 sync block succeed.
2019-05-05 14:41:19.439 INFO 60538 --- [main] c.w.w.crawler.service.BlockSyncService : Block 7 of 90 sync block succeed.
2019-05-05 14:41:20.303 INFO 60538 --- [main] c.w.w.crawler.service.BlockSyncService : Block 8 of 90 sync block succeed.
2019-05-05 14:41:20.512 INFO 60538 --- [main] c.w.w.crawler.service.BlockSyncService : Block 9 of 90 sync block succeed.
2019-05-05 14:41:20.738 INFO 60538 --- [main] c.w.w.crawler.service.BlockSyncService : Block 10 of 90 sync block succeed.
……
2.4.3 检查数据是否已经正常产生¶
你也可以通过DB来检查,登录你之前配置的数据库,看到自动创建完表的信息,以及表内开始出现数据内容,则代表一切进展顺利。如你可以执行以下命令:
# 请用你的配置信息替换掉[]里的配置,并记得删除[]
mysql -u[用户名] -p[密码] -e "use [数据库名]; select count(*) from block_detail_info"
如果查询结果非空,出现类似的如下记录,则代表导出数据已经开始运行:
+----------+
| count(*) |
+----------+
| 633 |
+----------+
2.4.5 注意事项¶
在生成的工程中,我们使用了Hibernate auto-ddl 的特性来自动创建数据库表,该特性仅供提供快速的演示,但请勿使用该特性上线;否则可能会造成生产系统的安全隐患。
你可以修改WeBASE-Collect-Bee/WeBASE-Collect/src/main/resources/appliction.properties:
spring.jpa.properties.hibernate.hbm2ddl.auto=none
3. 可视化监控程序安装和部署¶
3.1 安装软件¶
首先,请安装docker,docker的安装可参考docker安装手册 等docker安装成功后,请下载grafana:
docker pull grafana/grafana
如果你是使用sudo用户安装了docker,可能会提示『permission denied』的错误,建议执行:
sudo docker pull grafana/grafana
3.2 启动grafana¶
docker run -d -p 3000:3000 --name=grafana -e "GF_INSTALL_PLUGINS=grafana-clock-panel,grafana-simple-json-datasource" grafana/grafana
grafana将自动绑定3000端口并自动安装时钟和Json的插件。
3.3 登录grafana界面¶
直接使用浏览器访问:http://your_ip:3000/,请注意使用你机器的IP替换掉your_ip,默认的用户名和密码为admin/admin
3.4 添加MySQL数据源¶
在正常登录成功后,如图所示,选择左边栏设置按钮,点击『Data Sources』,选择『MySQL』数据源,随后按照提示的页面,配置 Host, Database, User 和 Password等。
 [添加步骤]
[添加步骤]
3.5 导入Dashboard模板¶
WeBASE-Codegen-Monkey会自动生成数据的dashboard模板,数据的路径位于:WeBASE-Collect-Bee/WeBASE-Collect-Bee-core/src/main/scripts/grafana/default_dashboard.json,请点击左边栏『+』,选择『import』,点击绿色按钮『Upload.json File』,选择刚才的WeBASE-Collect-Bee/src/main/scripts/grafana/default_dashboard.json文件,最后,点击『import』按钮。
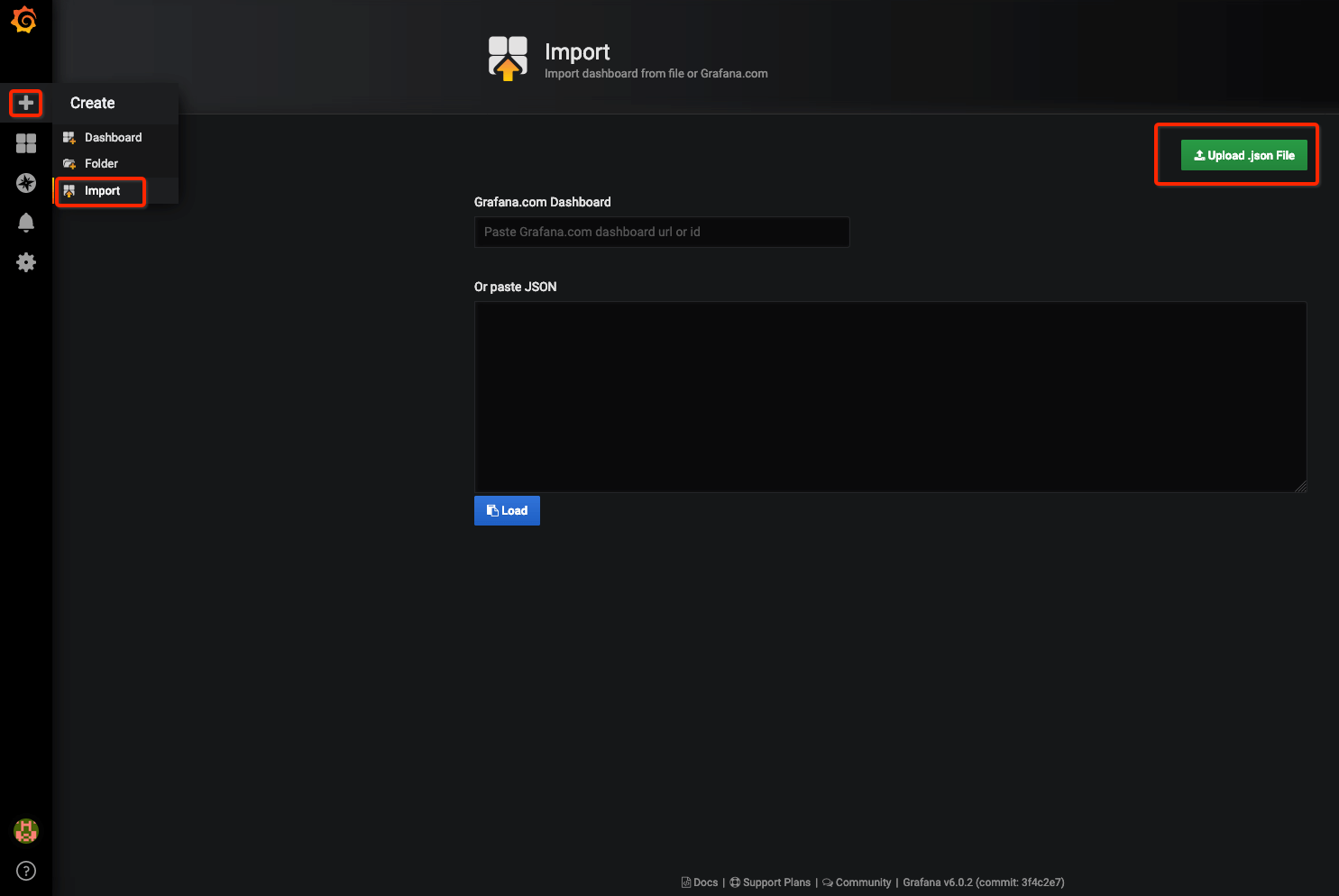 [导入步骤]
[导入步骤]
如果导入成功,dashboards下面会出现『FISCO-BCOS区块链监控视图』,您可以选择右上方的时间按钮来选择和设置时间范围及刷新时间等。您也可以选中具体的页面组件进行编辑,自由地移除或挪动组件的位置,达到更好的使用体验。
更多关于Grafana的自定义配置和开发文档,可参考Grafana官方文档
4. 开启可视化的API文档和功能性测试¶
WeBASE-Collect-Bee默认集成了swagger的插件,支持通过可视化的控制台来发送交易、生成报文、查看结果、调试交易等。
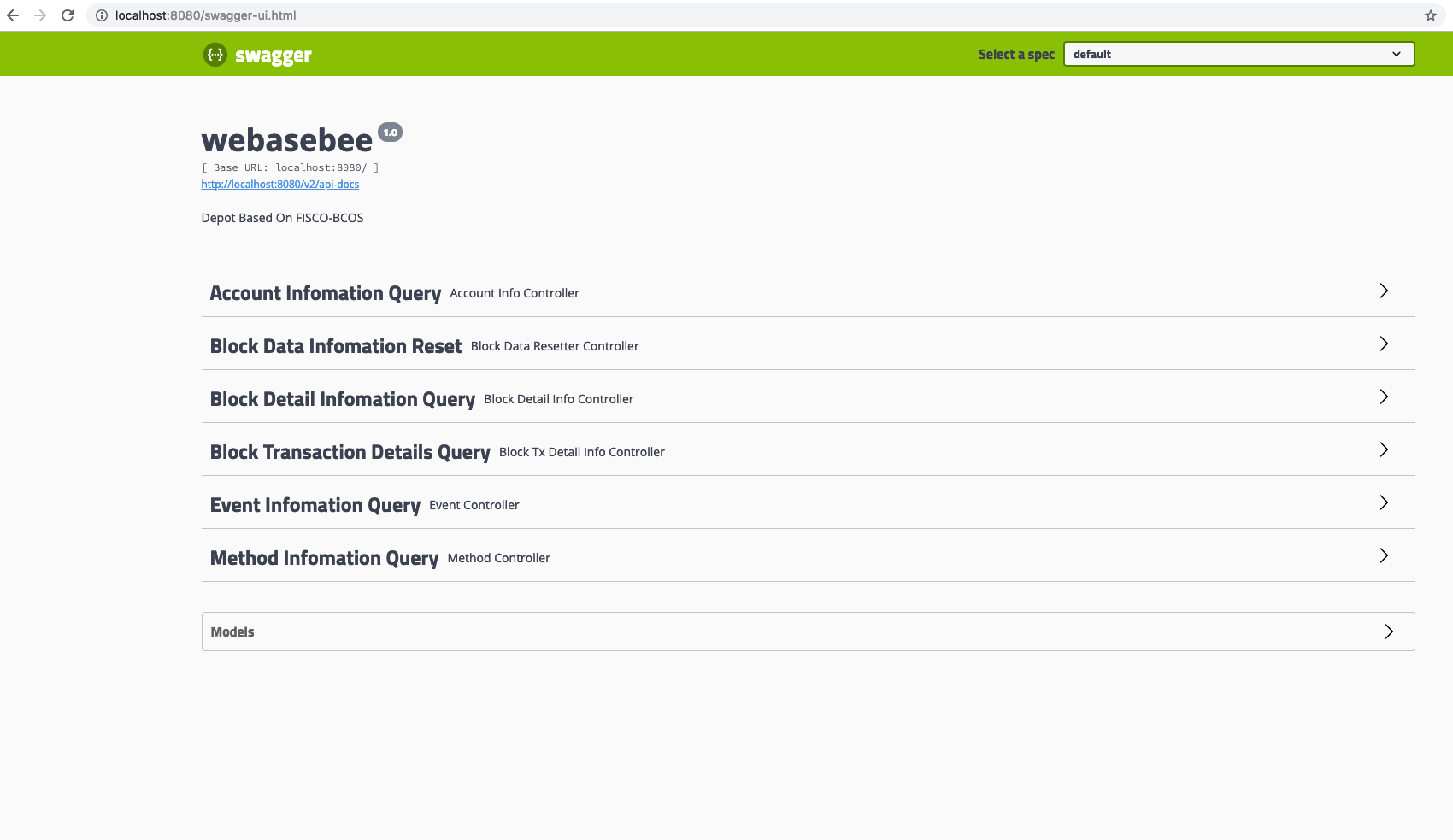 [swagger控制台]
[swagger控制台]
**请注意,swagger插件仅推荐在开发或测试环境调试使用,在正式上生产环境时,请关闭此插件。 **
如果未在monkey工程中配置打开swagger选项,则默认关闭,需要在配置文件中打开。
打开方法:
打开config/resources/application.properties,添加:
button.swagger=on
4.1 查看API文档:¶
请在你的浏览器打开此地址:
http://your_ip:port/swagger-ui.html
例如,当你在本机运行了WeBASE-Collect-Bee,且未修改默认的5200端口,则可以访问此地址:
http://localhost:5200/swagger-ui.html
此时,你可以看到上述页面,可以看到页面主要包括了http请求页面和数据模型两部分。
4.2 使用swagger发送具体的交易:¶
选择点击对应的http请求集,可以点开相关的http请求。此时,你可以选择点击“try it out”,手动修改发送的Json报文,点击“Excute”按钮,即可发送并查收结果。
我们以查询区块信息为例,如下列图所示:
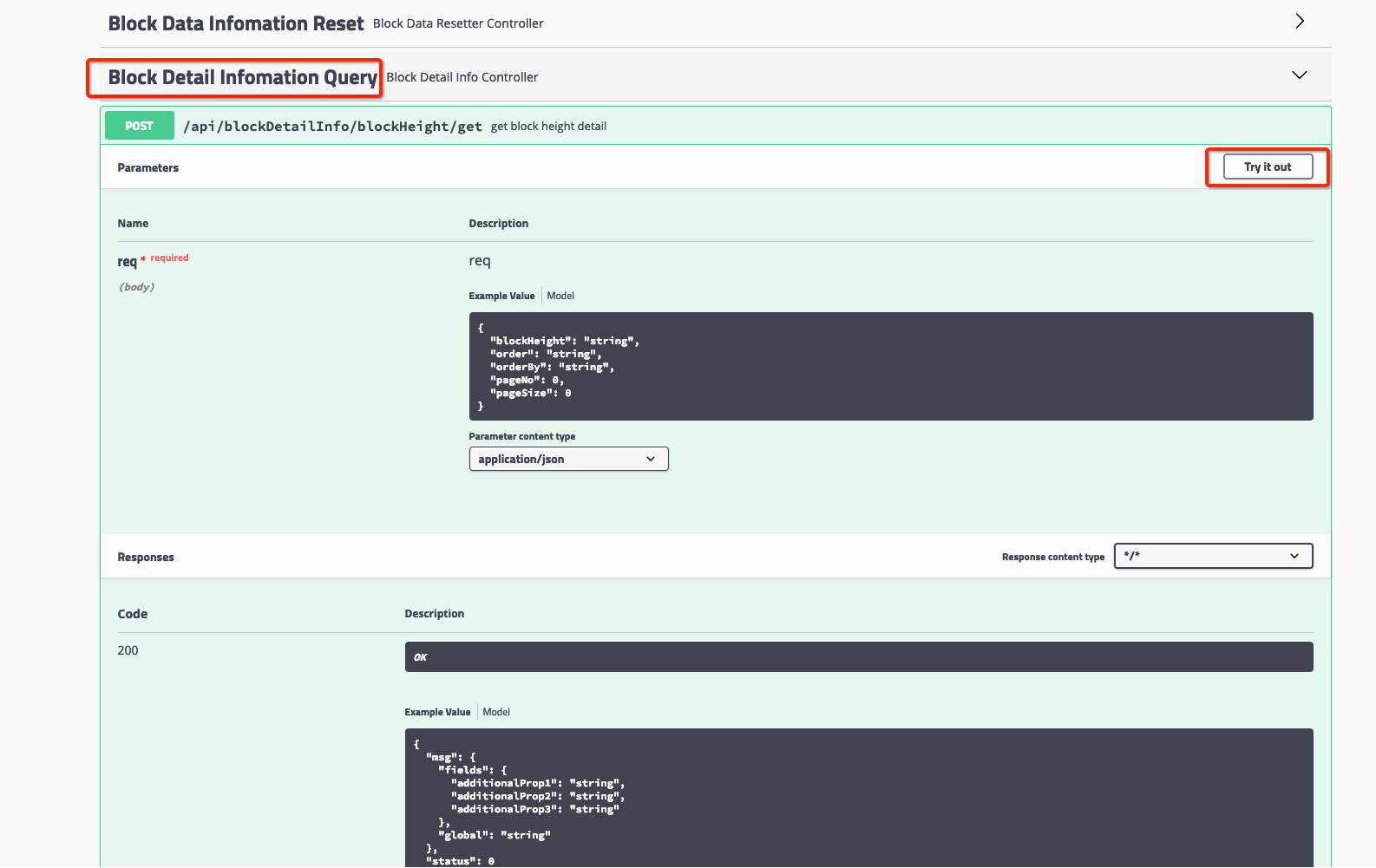 [选择请求]
[选择请求]
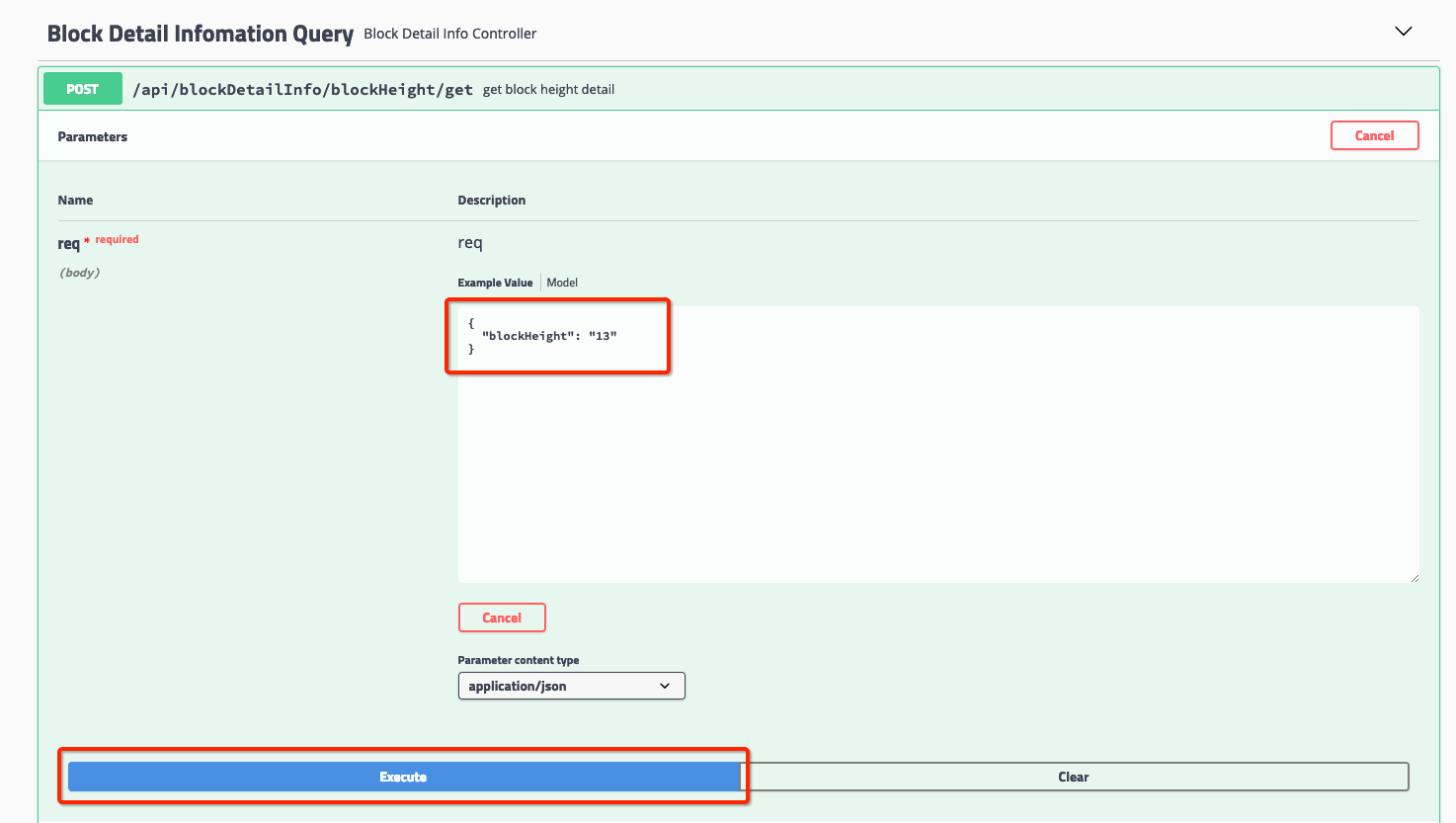 [编辑报文]
[编辑报文]
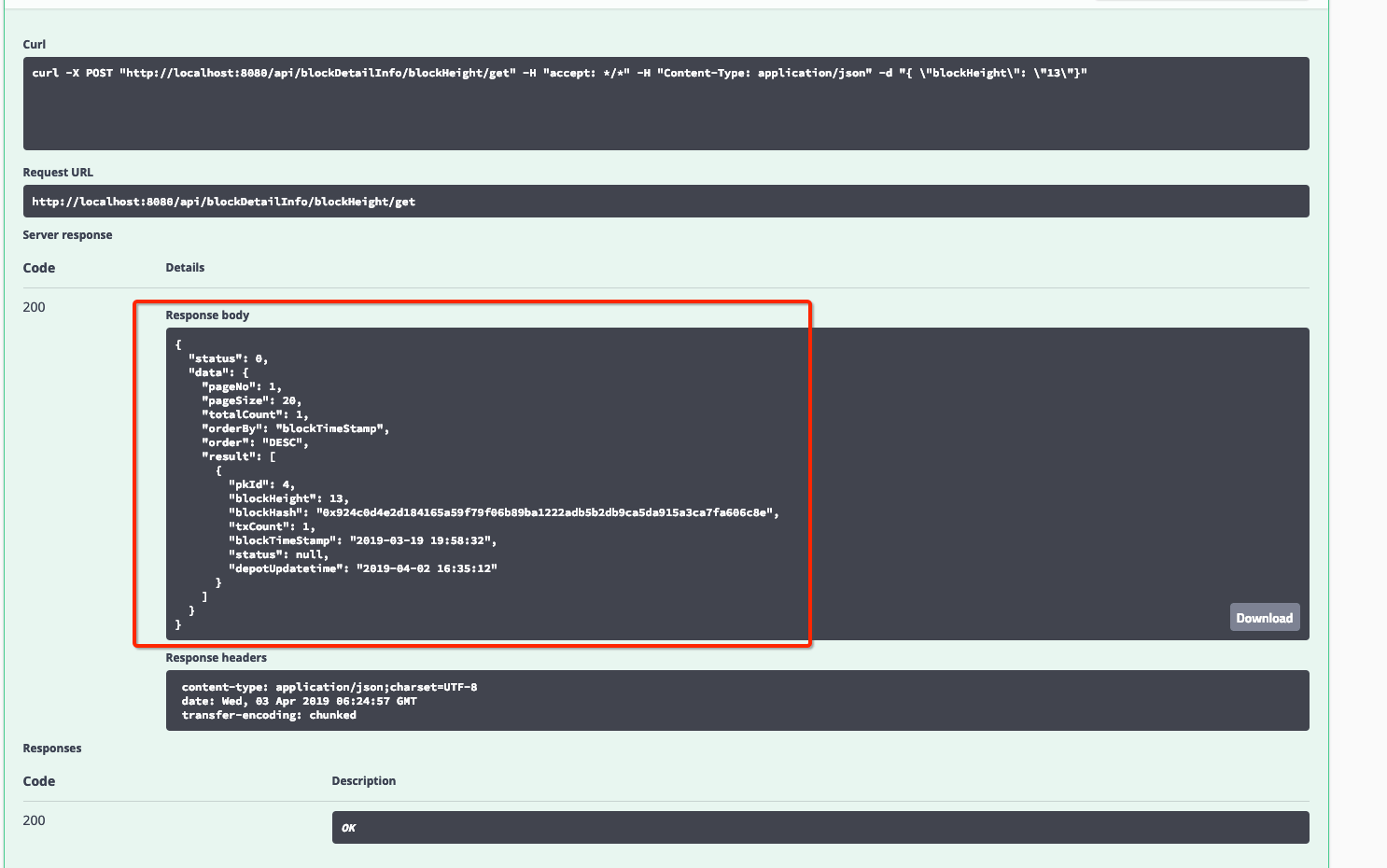 [查收结果]
[查收结果]